Figure 1: Python libraries for machine learning
During the last 10 years, we have witnessed a steep rise in the amount of data produced and consumed daily – an emergence of Big Data era.
Big Data in combination with affordable computing power has also led to a rising importance of data science and machine learning, two disciplines that help organizations produce insights from their data, automate their decisions or offer products that help us in our everyday lives, such as digital assistants on our mobile phones.
Growth of machine learning was accompanied with emergence of numerous libraries and tools in machine learning ecosystem, which help data scientists and others build their machine learning models and produce insights from them.
Although machine learning solutions can be developed in many different programming languages, Python is consistently one of the most popular languages for machine learning applications.
Github recently examined programming languages used in repositories tagged with the “machine-learning” topic. Python was found to be the most common language among these machine learning repositories, it was also the third most common language on Github overall.
Top machine learning languages on Github
| Python |
| C++ |
| Javascript |
| Java |
| C# |
| Julia |
| Shell |
| R |
| Typescript |
| Scala |
Source: Github
Rising popularity of Python is also visible from Google trends chart for the last five years:
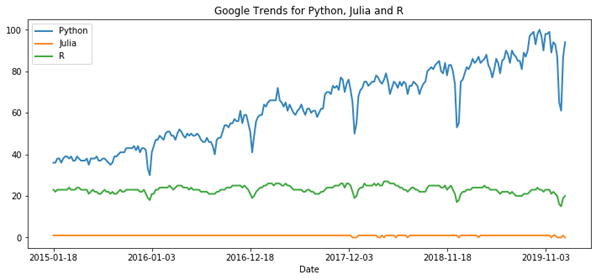
Figure 2: Google trends for programming languages Python, Julia and R
One of the advantages of Python for machine learning is a large ecosystem of libraries and tools, introducing the most important ones will be the focus of this article.
Machine learning libraries and tools in Python
Work on machine learning and deep learning problems involves steps that are common to most problems such as data pre-processing, data visualization, feature engineering. We will first introduce the most popular python based libraries that are typically used in these initial phases of work on machine learning problem, followed by the most popular frameworks for building and training machine learning and deep learning models.
Data processing
1. NumPy
Github stars: 12,737
NumPy is a package that provides powerful N-dimensional array objects with many advanced mathematical functions for operating on these arrays. NumPy arrays are especially advantageous when working with large amounts of data with main benefits being a smaller memory footprint and faster execution in comparison to standard Python.
2. SciPy
Github stars: 6,710
SciPy is a Python library for scientific and technical computing. It is a collection of mathematical algorithms and convenience routines built on the NumPy library and uses its arrays. It consists of many advanced modules for linear algebra, optimization, interpolation, FFT, image processing, ODE solvers and others.
3. Pandas
Github stars: 23,097
Pandas is a package that provides fast and flexible data structures that allow its users an easy and intuitive working with data. It is a high-level framework built on Python and one of the most popular tools for data analysis and data manipulation. Its main objects are Series and DataFrame, with Pandas supporting many useful operations such as label based slicing, merging and joining, hierarchical axis indexing, reshaping and pivoting of data.
Data visualization
4. Matplotlib
Github stars: 10,683
Matplotlib is the most popular library for data visualization in Python. It is built on Numpy arrays and works with the Scipy stack. It allows us to visualize our data sets in form of figures and plots. One of its strengths is that it works well with different operating systems and graphic output formats. Many of the newer packages such as Seaborn and HoloViews are built on Matplotlib functionality.
5. Bokeh
Github stars: 12,693
Bokeh is an interactive data visualization library, available for Python and other languages. It allows generation of rich, versatile interactive graphics for modern browsers. Bokeh plots are built by first creating a figure, which is then populated with glyphs (symbols that represent data). Bokeh is a great choice when building applications with dashboards and interactive plots.
6. Seaborn
Github stars: 6,760
Seaborn is a library for generating statistical graphs in Python, built on top of matplotlib and integrating Dataframes and Series data structures of Pandas library. Seaborn improves on matplotlib in areas of on styling and generating visually aesthetic charts and is working well with pandas data structures. It also provides visualizations of univariate and bivariate distributions, automatic plotting of linear regression models and other useful statistical charts.
7. Plotly
Github stars: 5,979
plotly.py is an interactive, open-source, and browser-based graphing library for Python. It is built on top of plotly.js, which in turn is built on top of Javascript and D3. plotly.js offers over 30 chart types, including scientific graphs, 3D charts, statistical charts, SVG maps, financial charts, and more. A useful supporting library is cufflinks, which helps plotly users in working with dataframes in Pandas.
Machine learning and deep learning libraries
8. Scikit-learn
Github stars: 39,001
Scikit-learn is one of the most popular libraries for machine learning in Python. It provides a large selection of standard supervised and unsupervised machine learning models. Scikit-learn has clean and efficient API, with a common syntax which allows you to easily switch between different models and algorithms. It also includes a lot of supporting methods, including ones for data preprocessing, data resampling, model evaluation metrics and hyperparameter tuning.
9. Tensorflow
Github stars: 140,175
Tensorflow was developed by Google and is among the most popular libraries for large-scale machine learning and deep learning. Tensorflow can be viewed as a tool for numerical computation of data flow graphs with nodes in graphs representing mathematical computations and edges representing tensors (multidimensional arrays). Tensorflow provides both high level APIs (such as tf.Keras) or low level APIs, if you need more granular control. It allows training across distributed servers and you can deploy Tensorflow solutions on desktops, servers, embedded IoT devices and mobile phones.
10. PyTorch
Github stars: 35,476
PyTorch is machine learning library based on Torch, which in turn is using programming language Lua. Main two features of PyTorch are tensor computations and automatic differentiation for building and training neural networks. PyTorch has become very popular in the last few years, one contributing feature to that is the ability to define your graph dynamically, unlike most of other deep learning libraries, which require you to set your computational graph before running your model.
11. Keras
Github stars: 46,477
Keras is a high-level neural networks API, which is capable of running on top of Tensorflow, Theano or CNTK. Keras was built with the purpose of allowing users fast experimenting and prototyping of ML models. It supports many deep learning architectures, including convolutional networks and recurrent networks. Keras was developed by François Chollet, who used several guiding principles in its development: modularity, user friendliness, easy extensibility and a requirement of working with python.
Other important machine learning libraries include Caffe, MXNet, CNTK, Chainer and Theano (ceased development).
Natural Language Processing
12. NLTK
Github stars: 8,553
NLTK (Natural Language Toolkit) is one of the leading platforms for natural language processing (NLP) with Python. It provides a wide range of methods for tokenization, tagging, parsing, stemming, classification and semantic understanding. One of its strengths are over 50 corpora and resources, including WordNet. NLTK also provides interfaces to other frameworks such as StanfordPOSTagger.
13. gensim
Github stars: 10,358
Gensim is one of the more popular libraries for natural language processing. Its name “Topic Modelling in Python” shows strong support for topic modelling with integrated methods such as Latent Semantic Analysis and Latent Dirichlet Allocation. Since its beginning it has however evolved in a versatile toolbox offering many other advanced NLP methods, including document index, similarity retrieval and support for many word embeddings, such as word2vec and GloVe.
14. spaCy
Github stars: 15,536
spaCy is a relative newcomer to the natural language processing space, when compared to older packages such as NLTK. Its developers have however included an impressive range of advanced NLP methods with fast implementation in Cython. spaCy comes with a large selection of pretrained statistical models and word vectors. It supports part-of-speech tagging, labelled dependency parsing, syntax-driven sentence segmentation, string-to-hash mappings, with visualizers for syntax and NER.
15. Stanford CoreNLP
Github stars: 6,896
Stanford CoreNLP is a widely used natural language analysis library. Although written in Java, there are several wrappers available for Python. It includes many advanced NLP tools, including part-of-speech tagger, the named entity recognizer (NER), parser, conference resolution methods, sentiment analysis and open information extraction tools. It supports many major human languages and has APIs available for most major programming languages.
Coming up with features is difficult, time-consuming, and requires expert knowledge. ‘Applied machine learning’ is basically feature engineering.
— Andrew Ng
Feature engineering
16. Featuretools
Github stars: 4,523
Feature engineering is a task that can be both time consuming but also very important. To speed up feature engineering, several libraries have been developed that automate this task. Featuretools is one of the most popular python frameworks for automated feature engineering. It operates with three key components: 1) entities (representation of Pandas DataFrame), 2) deep feature synthesis which enables creation of new features from existing ones and 3) feature primitives, which are typical methods for creation of features, e.g. a mean of a feature. Featuretools excels in problems involving large temporal and relational datasets.
17. Tsfresh
Github stars: 4,467
Tsfresh is a powerful python framework for automated feature extraction and feature selection for time series data sets. Tsfresh can automatically extract hundreds of features from time series. Features extracted range from simple, such as the number of peaks or average/maximum/minimum value to more complex ones, such as cross power spectral density or time reversal asymmetry statistic.
Image processing and augmentation
18. OpenCV
Github stars: 41,597
OpenCV (Open Source Computer Vision Library) is a computer vision and machine learning software library. It is specialized to provide a common platform for computer vision solutions. The OpenCV platform has more than 2500 algorithms, used for face detection and recognition, object identification, classification of human actions in videos, tracking of moving objects, extraction of 3D models of objects and many others. The library is used across many fields, in companies, research groups and by governmental bodies. It has interfaces for C++, Python, Java and MATLAB and supports Windows, Linux, Android and Mac OS.
19. scikit-image
Github stars: 3,451
scikit-image is a Python library for to image processing. It is using natively NumPy arrays as image objects. Scikit-image includes a wide range of algorithms – for segmentation, geometric transformations, color space manipulation, analysis, filtering, morphology, feature detection, and more. It is designed to be compatible with both NumPy and SciPy libraries.
20. imgaug
Github stars: 7,943
imgaug is a python library for image augmentation in machine learning. It comes with a lot of augmentation methods, allows easy combination of methods and their execution in random sequence or on multiple CPU cores. Imgaug also has a powerful stochastic interface and can not only augment images, but also keypoints/landmarks, bounding boxes, heatmaps and segmentation maps.
21. Augmentor
Github stars: 3,753
Augmentor is another popular Python image augmentation library for machine learning. Its goal is to be a standalone platform and framework independent, which more fine and granular control over augmentation, and implements the most relevant augmentation techniques. The package works by building an augmentation pipeline where you define a series of operations to perform on a set of images. Operations, such as rotations or transforms, are added sequentially to create an augmentation pipeline: when finished, the pipeline can be run and an augmented dataset is created.
“What is vital is to make anything about AI explainable, fair, secure and with lineage, meaning that anyone could see very simply see how any application of AI developed and why.” – Ginni Rometty
Explainable AI
22. Shap
Github stars: 7,652
SHAP (SHapley Additive exPlanations) is a python library that belongs in the group of model agnostic methods for explaining the outputs of machine learning models. It is based on game theory concepts of Shapley and it treats predictions as coalitional game involving features. It offers both global interpretability by providing information on importance of features across the whole data set, as well as local interpretability. The latter provides valuable information about predictions on individual data instances – which features contributed to the outcome for given prediction. SHAP library is one of the most popular tools in the field of Explainable Artificial Intelligence (XAI). The importance of XAI has risen in recent years by based on demands of consumers to obtain explanation for automated decisions affecting them, e.g. in finance and healthcare. An equally important driver for explainability of machine learning model decisions are laws and regulations such as GDPR. SHAP library provides local and global interpretability for a wide range of models, including tree based ones, such as XGBoost.
23. LIME
Github stars: 6,982
LIME (Local Interpretable Model-agnostic Explanations) is another popular python library that provides interpretability to machine learning models. In LIME approach, we learn about the importance of features in prediction for individual instance by slightly changing the input and observing the change in results of the model. Explanation is thus obtained with approximating our model with one that is linear and learned locally around our prediction.
Conclusion
One of the reasons for python success and popularity is a large ecosystem of excellent libraries for key tasks in machine learning: data pre-processing, feature engineering, exploratory data analysis with visualizations and a large number of machine learning libraries (scikit-learn, Tensorflow, Pytorch and others) with support for all standard machine and deep learning models. We have listed and presented a short introduction to some of the most important and popular machine learning libraries, which is however represents a part of the full and growing python ecosystem for machine learning tasks.


